
Today, I’ll guide you through the process of crafting your very own Python web crawler. I embarked on this endeavor after facing a challenge a few weeks ago when I needed to generate a sitemap for my website. If you’re unfamiliar with the term, a sitemap is essentially a comprehensive list of all the links or pages within your website. To accomplish this task, you require a program capable of systematically traversing your entire site and gathering all the links. My initial search for a free solution proved disappointing, as most free options were limited in terms of the number of pages they could handle. On the other hand, the paid alternatives were rather expensive for the task at hand. This predicament fueled my motivation to embark on the journey of building my own web crawler.
Admittedly, I must confess that I initially procrastinated and did not follow through with creating the crawler. However, a few days ago, while reviewing my website, I had an exhilarating idea: What if I could develop an open-source search engine customized specifically for my website? While tools like Google Custom Search exist for adding search functionality to a website, they often feel somewhat detached from the overall user experience of the site. This is when I revisited the idea of the web crawler I had contemplated earlier, and it suddenly appeared as a brilliant solution.
Therefore, the primary objective of this program, as outlined in this article series, is to systematically navigate through all the pages on your website and collect all the links they contain. This valuable information can be utilized to generate a sitemap or, for those with ambitious goals, to construct a custom search engine with detailed page analytics. This process forms the foundation of many web-related programs and applications, making it an essential skill to acquire.
Before we delve into the actual code, it’s important to mention a few Python modules. During my research, I encountered a module that piqued my interest, but unfortunately, it lacked support for Python 3 and didn’t align precisely with my objectives. On the other hand, the widely known BeautifulSoup module is excellent for parsing HTML, but we need to start with the fundamental task of gathering links.
To ensure versatility for future use, I intend to configure this program so that it can be employed on various websites. If you plan to use it on multiple sites, each site can be organized into its dedicated project folder. This approach prevents data from getting mixed up. Let’s go through the setup process:
Import the ‘os’ module, which will enable us to create directories. We’ll utilize separate project folders for each website we crawl.
Define a function called ‘create_project_directory’ to manage these project folders. It’s essential to ensure that the folder names do not conflict with any Python keywords, such as ‘dir.’
The program will automatically create a new folder when you initiate crawling for a new website. However, it’s crucial to handle scenarios where your computer unexpectedly shuts down or you need to pause the process. In such cases, we don’t want to lose any data. Therefore, when you rerun the program, it checks if the project directory already exists. If it does, it refrains from creating it again.
To provide clarity to users, we’ll include a message like “Creating project [project_name]” before generating the directory.
The ‘os.makedirs’ function will be employed to create the directory efficiently.
Before we proceed, let me clarify that the code snippet you saw earlier was just a demonstration to explain how we’ll structure our project folders. Now, let’s set up the foundation for our web crawler:
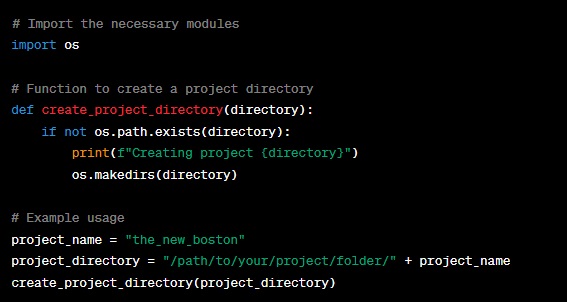
- We’ve imported the ‘os’ module, which is essential for creating directories.
- We’ve defined the ‘create_project_directory’ function, which takes a ‘directory’ parameter. This function checks if the directory already exists; if not, it creates it and prints a message to indicate that the project directory is being created.
- We’ve provided an example usage at the end of the code, where you can specify the ‘project_name’ and the ‘project_directory’ path. The ‘create_project_directory’ function will then create the project folder for you.
Remember that you can use this structure for multiple websites, ensuring that each website’s data remains separated and organized.
Now that we have our project structure in place, we’re ready to start building the web crawler itself. In the upcoming articles, we’ll delve into the code to create a functional web crawler that can gather links from websites efficiently.
Continuing on our journey to build a Python web crawler, let’s take the next steps in setting up our project and starting to code the crawler itself.
Project Structure: To recap, we’ve established a clear project structure where each website you intend to crawl will have its own designated project directory. This organization ensures that data remains separate and manageable, especially when you’re working with multiple websites.
Now, let’s proceed to create the core functionality of our web crawler.
Crawling Logic: Our web crawler’s primary objective is to navigate through a website’s pages and gather all the links it encounters. Here’s an overview of the crawling logic:
- Start by visiting the website’s homepage.
- Retrieve the HTML content of the homepage.
- Parse the HTML to extract all the links (URLs) present on that page.
- Store the gathered links for later processing.
- Move on to the next unprocessed link.
- Repeat steps 2-5 until you’ve crawled all the desired pages.
Python Modules: We’ll need several Python modules to achieve this, including:
- Requests: For fetching webpage content.
- BeautifulSoup: For parsing HTML.
- Queue or Stack (optional): To manage the order of URL processing.
Here’s a snippet to demonstrate the initial steps of our web crawler:
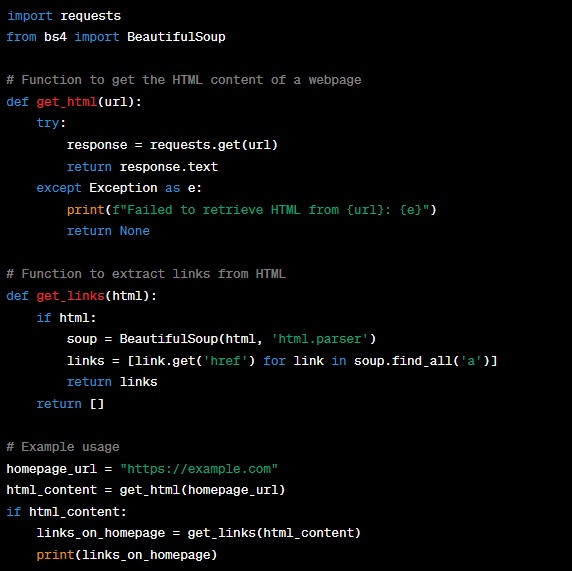
- We use the ‘requests’ module to fetch the HTML content of a webpage specified by the ‘url.’
- The ‘get_links’ function parses the HTML content using BeautifulSoup and extracts all the links (URLs) found in ‘a’ tags.
- The example usage demonstrates how to retrieve the HTML content of a homepage and extract its links.
This is just the beginning of our web crawler. In subsequent articles, we’ll expand upon this foundation, covering topics like managing the crawling process, dealing with different types of links, and saving data for analysis.
Managing the Crawling Process:
One crucial aspect of building a web crawler is managing the crawling process efficiently. To do this, we often employ a queue or stack data structure to keep track of the URLs we need to visit. This ensures that we systematically crawl all the desired pages without missing any.
Here’s a snippet that introduces a simple URL queue to manage the crawling process:
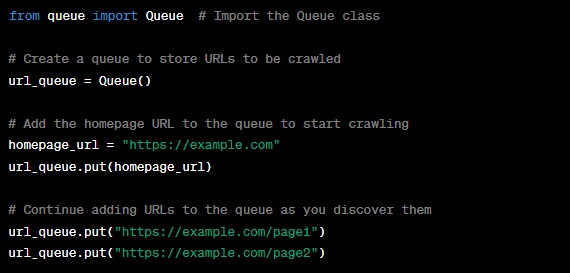
In this code:
- We import the ‘Queue’ class from the ‘queue’ module.
- We create a ‘url_queue’ object, which will store the URLs to be crawled.
- Initially, we add the homepage URL to the queue to kickstart the crawling process.
- As you discover more URLs during crawling, you can simply add them to the queue using the ‘put’ method.
Crawling Multiple Pages:
To crawl multiple pages, you’ll need a loop that retrieves URLs from the queue and processes them one by one. Here’s a snippet to demonstrate this:
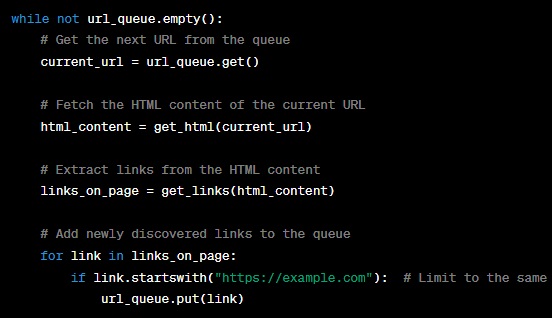
In this loop:
- We continuously check if the queue is not empty. If there are URLs left to process, we proceed.
- We retrieve the next URL from the queue using the ‘get’ method.
- We fetch the HTML content of the current URL using the ‘get_html’ function we previously defined.
- We extract links from the HTML content using the ‘get_links’ function.
- Finally, we add any newly discovered links that belong to the same domain back to the queue for further crawling.
Handling Different Types of Links:
In the previous section, we focused on crawling pages within the same domain. However, web pages often contain links in various formats, including relative and absolute URLs. We need to handle these different link types appropriately.
Here’s how you can modify your code to handle both relative and absolute links:
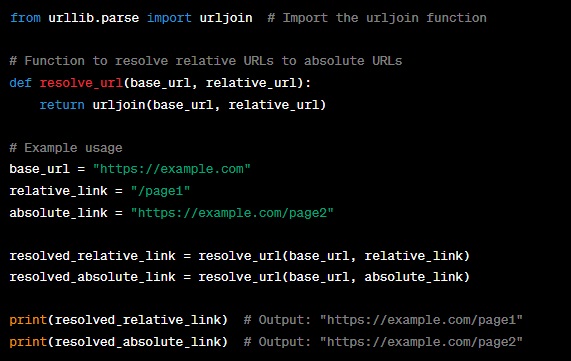
In this code:
- We import the ‘urljoin’ function from the ‘urllib.parse’ module, which is used to combine a base URL with a relative URL to create an absolute URL.
- We define the ‘resolve_url’ function, which takes a base URL and a relative URL and returns the resolved absolute URL.
- We demonstrate the usage of the ‘resolve_url’ function with both relative and absolute links.
Avoiding Duplicate URL Processing:
As your web crawler grows, you’ll encounter the same URLs multiple times, either due to links appearing on multiple pages or other reasons. It’s essential to avoid processing the same URL repeatedly to optimize your crawler.
One way to achieve this is by maintaining a set of visited URLs. Here’s how you can implement this:
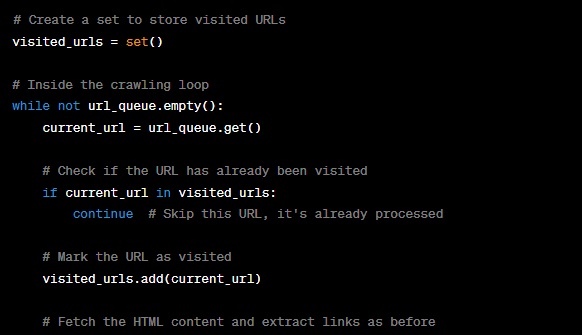
In this code:
- We create a ‘visited_urls’ set to store the URLs that have already been visited.
- Inside the crawling loop, before processing a URL, we check if it’s in the ‘visited_urls’ set.
- If the URL has been visited, we skip processing it and move on to the next URL.
- After processing a URL, we add it to the ‘visited_urls’ set to mark it as visited.
Saving Crawled Data:
To make your web crawler more useful, you can save the crawled data to files for further analysis. You might want to store information like the URL, page content, or metadata for later use.
Here’s a snippet demonstrating how to save crawled data to text files:
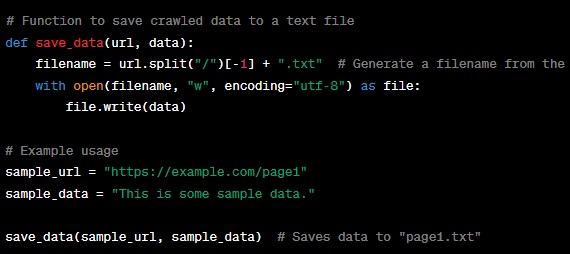
In this code:
- We define the ‘save_data’ function, which takes a URL and data as parameters.
- The function generates a filename from the URL by extracting the last part (usually the page name) and appending “.txt.”
- It then opens a text file with that filename and writes the data to it.
By saving crawled data, you can perform various analyses, such as text mining, content parsing, or even building a local search index.
Politeness and Rate Limiting:
As you continue to build your web crawler, it’s important to be mindful of web etiquette and avoid overloading websites with excessive requests. Politeness is key when web scraping or crawling. Here are some strategies to implement:
- Respect Robots.txt: Always check a website’s
robots.txtfile to see if it provides guidelines on what you can and cannot crawl. Follow these rules diligently. - Use User-Agent: Set a user-agent string in your requests headers to identify your crawler. Make it descriptive but not misleading, so website administrators can contact you if necessary.
- Implement Rate Limiting: Control the frequency of your requests to avoid bombarding a website. You can introduce delays between requests using the
time.sleepfunction.
Here’s an example of how to add rate limiting to your web crawler:
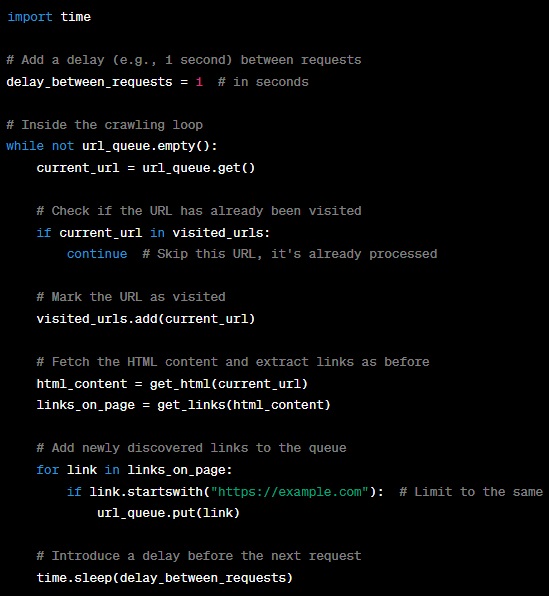
In this code:
- We’ve added the
time.sleepfunction to introduce a delay between requests, specified in seconds. - After processing a URL and before moving on to the next, we pause for the designated delay.
Handling Errors:
Web crawling can be unpredictable, and errors may occur for various reasons, such as network issues or invalid URLs. It’s important to handle errors gracefully to ensure your crawler continues to run smoothly.
Here’s an example of how to handle errors in your web crawler:
In this code:
- We wrap the code that fetches HTML content and extracts links in a
tryblock. - If an exception occurs, we catch it and print an error message.
- This prevents a single error from halting the entire crawling process.
By incorporating these strategies, you’ll make your web crawler more robust, respectful, and error-tolerant.
Advanced Data Storage:
To take your web crawler to the next level, consider advanced data storage options such as using databases like SQLite or MongoDB to store crawled data efficiently. This allows for more structured storage and easier data retrieval and analysis.
Our adventure to create a Python web crawler has led us through fundamental and advanced areas of web crawling and scraping. We’ve gone through everything from creating the project structure to dealing with various forms of links, avoiding duplicate URL processing, and applying courtesy and rate limiting. We’ve also spoken about error handling and ideas for making our web crawler more robust and resilient.
We’ve highlighted the necessity of ethical web crawling methods throughout this trip, such as following robots.txt requirements, utilizing suitable user-agent strings, and being mindful of the websites we crawl. These methods not only ensure that our web crawler is operating within legal and ethical constraints, but they also establish positive relationships with web administrators.
Web crawling has shown to be an effective tool for web developers, data junkies, and researchers. Web crawlers, with its ability to collect and analyze data from the wide internet environment, have uses ranging from SEO improvement and content indexing to data mining and research. As we wrap out this series, keep in mind that web crawling is a constantly expanding field with always more to learn and explore. Whether you want to develop search engines, do market research, or simply explore the depths of the web, the information and abilities you’ve obtained here will give a solid basis for your web crawling excursions.
Remember that appropriate and ethical web crawling methods are critical, and always be respectful to the websites with which you interact. As you progress through your web crawling journey, you’ll discover that it’s not just about what you can learn from the web, but also about the positive influence you can make by contributing to the online ecosystem in a thoughtful and responsible manner. Thank you for joining us on this web crawling adventure, and best wishes for your future web crawling activities!